Parsing Epubs
Recently I've become frustrated with the experience of reading books on my Kindle Paperwhite. The swipe features, really bother me. I really like MoonReader on Android, but reading on my phone isn't always pleasing. This lead me to look into other hardware. I've been eyeing the BOOX company a while ago, but definitely considering some of their new offerings some time. Until the time I can afford the money to splurge on a new ebook reader, I've decided to start a new project, making my own ebook reader tools!
I'm starting with EPUBs, as this is one of the easiest to work with. At its core, an EPUB is a zip file with the .epub extension instead of .epub with many individual XHTML file chapters inside it. You can read more of how they're structured yourself over at FILEFORMAT.
The tool I've chosen for reading EPUBs is the Python library ebooklib. This seemed to be a nice lightweight library for reading EPUBs. I also used DearPyGUI for showing this to the screen, because I figured why not, I like GUI libraries.
My first task was to find an EPUB file, so I downloaded one from my calibre server. I convert all my ebook files to .epub and .mobi on my calibre server so I can access them anywhere I can read my OPDS feed. I chose Throne of Glass (abbreviating to TOG.epub for rest of post). Loading I launched Python, and ran
>>> from ebooklib import epub
>>> print(book := epub.read_epub("TOG.epub")
This returned me a <ebooklib.epub.EpubBook object...> , seeing I had an EpubBook I ran a dir(book) and found the properties available to me
['add_author', 'add_item', 'add_metadata', 'add_prefix',
'bindings', 'direction', 'get_item_with_href', 'get_item_with_id',
'get_items', 'get_items_of_media_type', 'get_items_of_type',
'get_metadata', 'get_template', 'guide',
'items', 'language', 'metadata', 'namespaces', 'pages', 'prefixes',
'reset', 'set_cover', 'set_direction', 'set_identifier', 'set_language',
'set_template', 'set_title', 'set_unique_metadata', 'spine',
'templates', 'title', 'toc', 'uid', 'version']
Of note, the get_item_with_X entries caught my eye, as well as spine. For my file, book.spine looks like it gave me a bunch of tuples of ID and a "yes" string of which I had no Idea what was. I then noticed I had a toc property, assuming that was a Table of Contents, I printed that out and saw a bunch of epub.Link objects. This looks like something I could use.
I will note, at this time I was thinking that this wasn't the direction I wanted to take this project. I really wanted to learn how to parse these things myself, unzip, parse XML, or HTML, etc., but I realized I needed to see someone else's work to even know what is going on. With this "defeat for the evening" admitted, I figured hey, why not at least make SOMETHING, right?" I decided to carry on.
Seeing I was on at least some track, I opened up PyCharm and made a new Project. First I setup a class called Epub, made a couple of functions for setting things up and ended up with
class Epub:
def __init__(self, book_path: str) -> None:
self.contents: ebooklib.epub.EpubBook = epub.read_epub(book_path)
self.title: str = self.contents.title
self.toc: List[ebooklib.epub.Link] = self.contents.toc
I then setup a parse_chapters file, where I loop through the TOC. Here I went to the definition of Link and saw I was able to get a href and a title, I decided my object for chapters would be a dictionary (I'll move to a DataClass later) with title and content. I remembered from earlier I had a get_item_by_href so I stored the itext from the TOC's href: self.contents.get_item_with_href(link.href).get_content(). This would later prove to be a bad decision when I opened "The Fold.epub" and realized that a TOC could have a tuple of Section and Link, not just Links. I ended up storing the item itself, and doing a double loop in the parse_chapters function to loop if it's a tuple.
def parse_chapters(self) -> None:
idx = 0
for _item in self.toc:
if isinstance(_item, tuple): # In case is section tuple(section, [link, ...])
for link in _item[1]:
self._parse_link(idx, link)
idx += 1
else:
self._parse_link(idx, _item)
idx += 1
_parse_link simply makes that dictionary of title and item I mentioned earlier, with a new index as I introduced buttons in the DearPyGUI at this time as well.
def _parse_link(self, idx, link) -> None:
title = link.title
self.chapters.append(dict(
index=idx,
title=title,
item=self.contents.get_item_with_href(link.href)
))
That's really all there is to make an MVP of an EPUB parser. You can use BeautifulSoup to parse the HTML from the get_body_contents() calls on items, to make more readable text if you want, but depending on your front end, the HTML may be what you want.
In my implementation my Epub class keeps track of the currently selected chapter, so this loads from all chapters and sets the current_text variable.
def load_view(self) -> None:
item = self.chapters[self.current_index]['item']
soup = BeautifulSoup(item.get_body_content(), "html.parser")
text = [para.get_text() for para in soup.find_all("p")]
self.current_text = "\n".join(text)
I don't believe any of this code will be useful to anyone outside of my research for now, but it's my first step into writing an EPUB parser myself.
The DearPyGUI steps are out of scope of this blog post, but here is my final ebook Reader which is super inefficient!
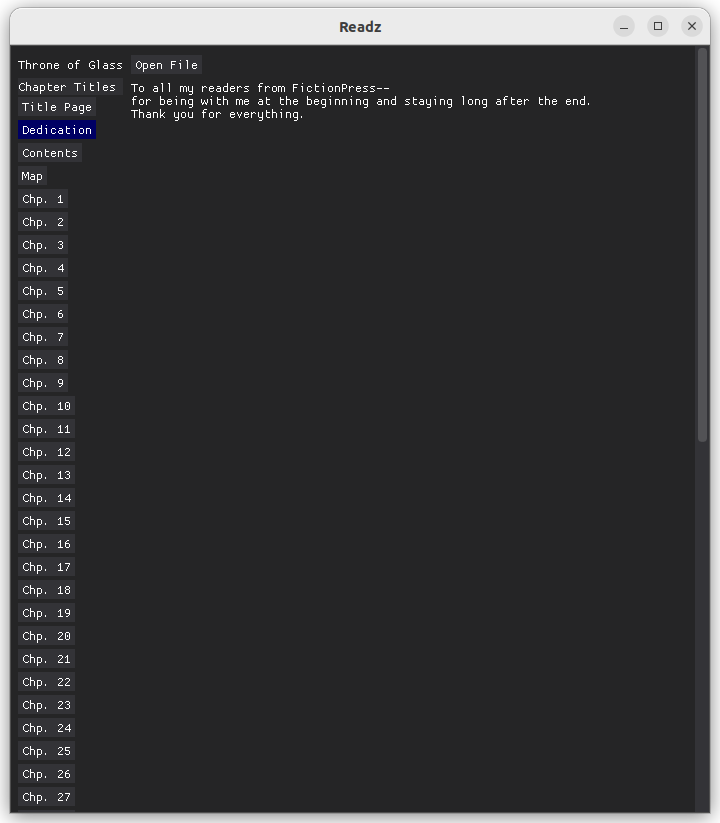
I figure the Dedication page is not as copywrited as the rest of the book, so it's fair play showing that much. Sarah J Maas, if you have any issues, I can find another book for my screenshots.